Mapping where the frustration actually lived.
With research synthesized and technical constraints understood, we mapped the current experience as operators actually lived it, not as the documentation described it.
The as-is journey followed six stages:
Login → Scan & Import → Organize → Review → Annotate → Submit
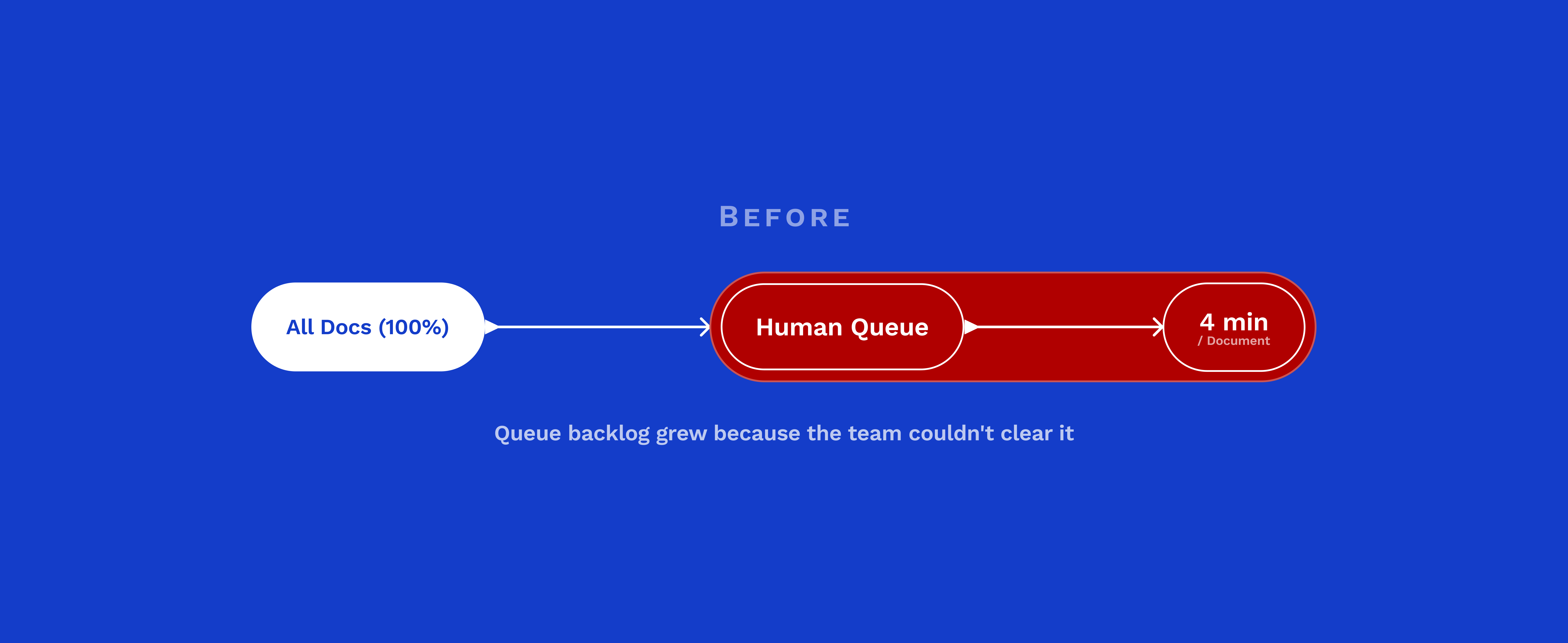
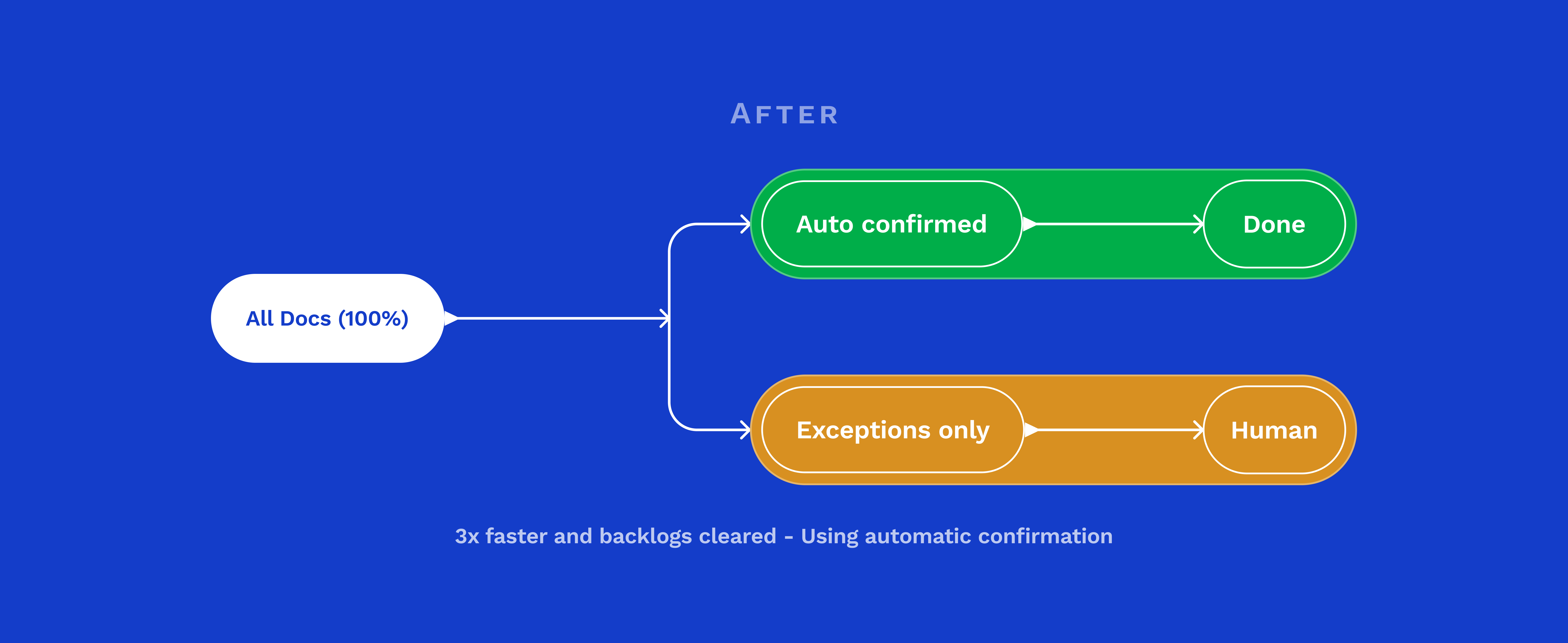
On paper, a clean six-step flow. In practice, the Review stage was where the day broke down.
User frustration peaks during the Review stage, not because the task is inherently difficult, but due to the absence of clear signals from the interface. Operators are left in the dark about field accuracy, document urgency, and prior reviews.
The system possesses this knowledge, but the user experience does not convey it, leading to inefficiencies.
Every HMW opportunity on the journey map pointed back to the same place: the Review stage. That's where the design work needed to focus.